
Python基础
Python
第一个Python 程序
输入和输出
1 | print('Hello, world') |
1 | input('input your name') |
1 | print("%d * %d = %d" % (1024, 768, 1024 * 768)) |
Python 基础
数据类型和变量
1 | print -1 |
整数
1 | # 八进制 |
浮点数
1 | print 0.1234567890 |
字符串
1 | print '123' |
布尔值
1 | # 与 |
空值
1 | print None is None |
变量
1 | # 在Python中,等号=是赋值语句,可以把任意数据类型赋值给变量, |
常量
1 | # 在Python中,通常用全部大写的变量名表示常量: |
运算符和表达式
| 表1 | 运算符与它们的用法 | - | - |
|---|---|---|---|
| 运算符 | 名称 | 说明 | 例子 |
| + | 加 | 两对象相加;对象可以是数字/字符(串) | 3 + 5 = 8 ; ‘a’ + ‘b’ = ‘ab’ |
| − | 减 | 两数字相减;取负数 | 5 - 3 = 2 ; -1 = -1 |
| * | 乘 | 两数字相乘;取重复N次字符串 | 2 * 2 = 4 ; ‘ha’ * 3 = ‘hahaha’ |
| ** | 幂 | 返回xy | x = 2; y = 3; x ** y = 8; |
| / | 除 | 两数字相除;两整数相除只会返回整数 | 5 / 2 = 2; 5.0 / 2 = 2.5; 5 / 2.0 = 2.5; |
| // | 除取整 | 两数字相除取整数部分 | 5 //2 = 2; 5.0 //2 = 2.0; 5 //2.0 = 2.0; |
| % | 除取余 | 两数字相除取余数部分 | 5 % 2 = 1; 5.0 % 2 = 1.0; 5 % 2.0 = 1.0; |
| << | 左移 | 左移N个比特位 | 2 << 2 = 8; 10 -> 1000 |
| >> | 右移 | 右移N个比特位 | 9 >> 2 = 2; 1001-> 10 |
| & | 按位与 | - | - |
| | | 按位或 | - | - |
| ^ | 按位异或 | - | - |
| ∼ | 按位翻转 | x -> -(x+1) | - |
| < | 小于 | - | - |
| > | 大于 | - | - |
| ≤ | 小于等于 | - | - |
| ≥ | 大于等于 | - | - |
| ⩵ | 等于 | - | - |
| ≠ | 不等于 | - | - |
| and | 布尔”与” | - | - |
| or | 布尔”或” | - | - |
| not | 布尔”非” | - | - |
| 表2 | 运算符优先级 | - | - |
|---|---|---|---|
| 运算符 | 描述 | - | - |
| lambda | Lambda表达式 | - | - |
| or | 布尔“或” | - | - |
| and | 布尔“与” | - | - |
| not x | 布尔“非” | - | - |
| in, not in | 成员测试 | - | - |
| is, is not | 同一性测试 | - | - |
| <, <=, >>=, !=, == | 比较 | - | - |
| | | 按位或 | - | - |
| ^ | 按位异或 | - | - |
| & | 按位与 | - | - |
| <<, >> | 移位 | - | - |
| +, - | 加法与减法 | - | - |
| *, /, % | 乘法、除法与取余 | - | - |
| +x, -x | 正负号 | - | - |
| ~x | 按位翻转 | - | - |
| ** | 指数 | - | - |
| x.attribute | 属性参考 | _ | self.name |
| x[index] | 下标 | _ | list[0] |
| x[index:index] | 寻址段 | _ | list[1:3] |
| f(arguments…) | 函数调用 | _ | f(args) |
| (expression, …) | 绑定或元组显示 | - | - |
| [expression, …] | 列表显示 | - | - |
| {key:datum, …} | 字典显示 | - | - |
| ‘expression, …’ | 字符串转换 | - | - |
1 | print(" 9 / 3 = {}".format(9 / 3)) |
字符串和编码
List和Tuple
| 操作 | 方法 | 描述 | 说明 |
|---|---|---|---|
| 增 | L.append(object) | append object to end | 在列表尾部追加对象 |
| 增 | L.insert(index, object) | insert object before index | 在index之前插入对象 |
| 增 | L.extend(iterable) | extend list by appending elements from the iterable | |
| 删 | L.remove(value) | remove first occurrence of value. | 移除首次出现的value |
| 删 | L.pop([index]) -> item | remove and return item at index (default last). | 移除index位置的值 |
| 改 | L.sort(cmp=None, key=None, reverse=False) | stable sort IN PLACE | 列表排序 |
| 改 | L.reverse() | reverse IN PLACE | 颠倒列表 |
| 查 | L.count(value) -> integer | return number of occurrences of value | 查询value出现次数 |
| 查 | L.index(value, [start, [stop]]) -> integer | return first index of value. | 查询value首次出现的位置 |
Dict和Set
Dictionary
Python 字典 setdefault() 函数和get() 方法类似, 如果键不存在于字典中,将会添加键并将值设为默认值。
1 | D = {'a': 1, 'b': 2, 'c': 3} |
1 | D = {'a': 1, 'b': 2, 'c': 3, 'd': 4} |
1 | # l = [0,'a','b','c','d','e','f'] |
条件语句
循环语句
函数
高级特性
切片
列表生成式
1 | # 列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式。 |
生成器(generator)
1 | # 第一种创建generator的方法就是将列表生成式的中括号改为圆括号即可 |
1 | print(next(g)) |
斐波拉契数列(Fibonacci)
1 | # 斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数 |
迭代器
函数式编程
高阶函数
1 | help(filter) |
1 | def odd(x): |
map & reduce
MapReduce: Simplified Data Processing on Large Clusters
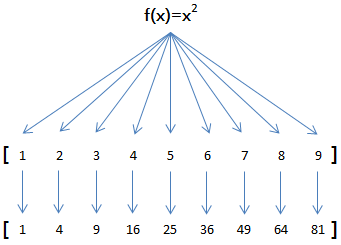
map
reduce
1 | [x1, x2, x3, x4].reduce(f) = f(f(f(x1, x2), x3), x4) |
1 | def pow(x): |
返回函数
匿名函数
1 | def div(x, y): |
装饰器(Decorator)
1 | # -*- coding: utf-8 -*- |
1 | # -*- coding: utf-8 -*- |
1 | # -*- coding: utf-8 -*- |
1 | # -*- coding: utf-8 -*- |
1 | # -*- coding: utf-8 -*- |
偏函数
模块
- 一个目录里面存在__init__.py就是一个包(package)
- 一个py文件就是一个模块(module)
1 | # import |
1 | # from ... import |
1 | # dir() |
1 | import subprocess |
1 | import multiprocessing |
1 | import threading |
datetime
1 | from datetime import date |
1 | # datetiem是一个模块 |
1 | # 里面还有一个datetime类 |
time
1 | import time |
1 | import time |
json
1 | import json |
urllib
1 | import urllib |
1 | url = 'https://api.douban.com/v2/book/2129650' |
1 | f = urllib.urlopen(url) |
Deprecated since version 2.6: The urlopen() function has been removed in Python 3 in favor of urllib2.urlopen().
1 | import urllib2 |
1 | try: |
正则表达式
1 | import re |
1 | x = 15435627401 |
面向对象编程
1 | class Person(): |
错误、调试和测试
I/O编程
进程和线程
多进程
1 | from multiprocessing import Process |
进程池
1 | from multiprocessing import Pool |
多线程
1 | import threading |